-
DSO-1 and DSI-1 Datasets (Digital Forensics)
-
Pornography-2k Dataset & TRoF (Sensitive Media Analysis)
-
Micro-messages Dataset (Authorship Attribution)
-
Flickr-dog Dataset (Vision)
-
VGDB-2016 (Painter Attribution)
-
UVAD Dataset (Biometric Spoofing Detection)
-
Diabetic Retinopathy Datasets (Medical Imaging)
-
Multimedia Phylogeny Datasets (Digital Forensics)
-
Supermarket Produce Dataset (Vision)
-
RECODGait Dataset (Digital Forensics)
-
Going Deeper into Copy-Move Forgery Detection (Digital Forensics)
-
Behavior Knowledge Space-Based Fusion for Copy-Move Forgery Detection (Digital Forensics)
-
Eyes on the Target: Super-Resolution and License-Plate Recognition in Low-Quality Surveillance Videos
 DSO-1 and DSI-1 Datasets
DSO-1 and DSI-1 Datasets

Authors: Tiago Carvalho, Christian Riess, Elli Angelopoulou, Hélio Pedrini, Fabio Faria, Ricardo Torres, and Anderson Rocha.
Related publication:
T. J. d. Carvalho, C. Riess, E. Angelopoulou, H. Pedrini and A. d. R. Rocha, “Exposing Digital Image Forgeries by Illumination Color Classification,” in IEEE Transactions on Information Forensics and Security, vol. 8, no. 7, pp. 1182-1194, July 2013. doi: doi: 10.1109/TIFS.2013.2265677
T. Carvalho, F. A. Faria, H. Pedrini, R. da S. Torres and A. Rocha, “Illuminant-Based Transformed Spaces for Image Forensics,” in IEEE Transactions on Information Forensics and Security, vol. 11, no. 4, pp. 720-733, April 2016. doi: doi: 10.1109/TIFS.2015.2506548
Overview:
DSO-1 It is composed of 200 indoor and outdoor images with an image resolution of 2,048 x 1,536 pixels. Out of this set of images, 100 are original, i.e., have no adjustments whatsoever, and 100 are forged. The forgeries were created by adding one or more individuals in a source image that already contained one or more persons.
DSI-1 It is composed of 50 images (25 original and 25 doctored) downloaded from different websites in the Internet with different resolutions. Original images were downloaded from Flickr and doctored images were collected from different websites such as Worth 1000, Benetton Group 2011, Planet Hiltron, etc.
The source-code is available on GitHub.
 Pornography-2k Dataset & TRoF
Pornography-2k Dataset & TRoF

Authors: Daniel Moreira, Sandra Avila, Mauricio Perez, Daniel Moraes, Vanessa Testoni, Eduardo Valle, Siome Goldenstein, and Anderson Rocha.
Related publication:
D. Moreira; S. Avila; M. Perez; D. Moraes; V. Testoni; E. Valle; S. Goldenstein; A. Rocha., “Pornography Classification: The Hidden Clues in Video Space-Time” in Forensic Science International, vol. 268, November 2016, p. 46-61, doi: doi: 10.1016/j.forsciint.2016.09.010
D. Moreira, S. Avila, M. Perez, D. Moraes, V. Testoni, E. Valle, S. Goldenstein, and A. Rocha, “Temporal Robust Features for Violence Detection,” 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, 2017, pp. 391-399. https://doi.org/10.1109/WACV.2017.50
TRoF – Temporal Robust Features: Temporal Robust Features (TRoF) comprise a spatiotemporal video content detector and a descriptor developed to present low-memory footprint and small runtime. It was shown to be effective for the tasks of pornography and violence detection. Please refer to both articles for further technical details.
Overview: The Pornography-2k dataset is an extended version of the Pornography-800 dataset, originally proposed in [1]. The new dataset comprises nearly 140 hours of 1,000 pornographic and 1,000 non-pornographic videos, which varies from six seconds to 33 minutes. Concerning the pornographic material, unlike Pornography-800 [1], we did not restrict to pornography-specialized websites. Instead, we also explored general-public purpose video networks, in which it was surprisingly easy to find pornographic content. As a result, the new Pornography-2k dataset is very assorted, including both professional and amateur content. Moreover, it depicts several genres of pornography, from cartoon to live action, with diverse behavior and ethnicity. With respect to non-pornographic content, we proceeded similarly to Avila et al. [1]. We collected easy samples, by randomly selecting files from the same general-purpose video networks. Also, we collected difficult samples, by selecting the result of textual queries containing words such as “wrestling”, “sumo”, “swimming”, “beach”, etc. (i.e., words associated to skin exposure). The data is available free of charge to the scientific community but, due to the potential legal liabilities of distributing large quantities of pornographic/copyrighted material, the request must be formal and a responsibility term must be signed. Thus, if you are interested please contact Prof. Anderson Rocha.
[1] S. Avila, N. Thome, M. Cord, E. Valle, A. Araújo, Pooling in image representation: the visual codeword point of view, Computer Vision and Image Understanding, vol. 117, p. 453-465, 2013.
 Micro-messages Dataset
Micro-messages Dataset
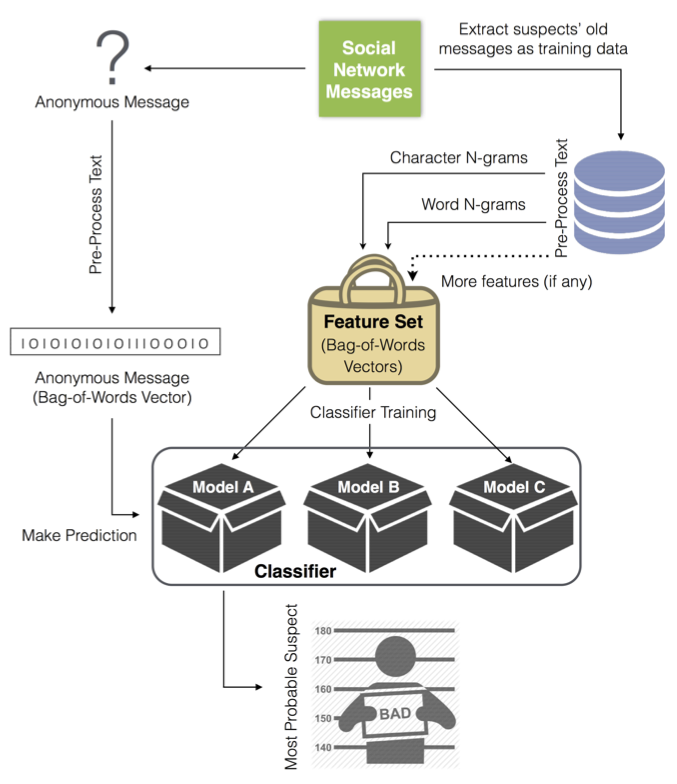
Authors: Anderson Rocha, Walter J. Scheirer, Christopher W. Forstall, Thiago Cavalcante, Antonio Theophilo, Bingyu Shen, Ariadne R. B. Carvalho and Efstathios Stamatatos
Related publication: A. Rocha; W. Scheirer; C. Forstall; T. Cavalcante; A. Theophilo; B. Shen; A. Carvalho; E. Stamatatos, Authorship Attribution for Social Media Forensics in IEEE Transactions on Information Forensics and Security , vol.PP, no.99, pp.1-1 doi: 10.1109/TIFS.2016.2603960
Overview: The set was constructed by searching Twitter for the English language function words, yielding results from English speaking public users. These results were used to build a list of public users from which we could extract tweets by using the Twitter API. We collected ten million tweets from 10,000 authors (the Twitter API only allows the extraction of the most recent 3,200 tweets from a user) over the course of six months in 2014. Each tweet is at most 140-character long and includes hashtags, user references and links. While we cannot release the actual messages, we release all of the features derived from them in an effort to provide the community with a standardized resource for evaluation. Thus, if you are interested please contact Prof. Anderson Rocha. The source-code is available on GitHub.
 Flickr-dog Dataset
Flickr-dog Dataset

Authors: Thierry Pinheiro Moreira, Mauricio Lisboa Perez, Rafael de Oliveira Werneck and Eduardo Valle
Related publication: Moreira, T.P., Perez, M.L., Werneck, R.O., Valle, E. Where is my puppy? Retrieving lost dogs by facial features. Multimed Tools Appl (2016). doi:10.1007/s11042-016-3824-1
Overview: We acquired the Flickr-dog dataset 6 by selecting dog photos from Flickr available under Creative Commons licenses. We cropped the dog faces, rotated them to align the eyes horizontally, and resized them to 250×250 pixels. We selected dogs from two breeds: pugs and huskies. Those breeds were selected to represent the different degrees of challenge: we expected pugs to be difficult to identify, and huskies to be easy. For each breed, we found 21 individuals, each with at least 5 photos. We labeled the individuals by interpreting picture metadata (user, title, description, timestamps, etc.), and double checked with our own ability to identify the dogs. Altogether, the Flickr-dog dataset has 42 classes and 374 photos.
 VGDB-2016
VGDB-2016

Authors:Guilherme Folego, Otavio Gomes and Anderson Rocha
Related publication: Folego, G., Gomes, O. and Rocha, A., 2016. From impressionism to expressionism: Automatically identifying van Gogh’s paintings. In Image Processing (ICIP), 2016 IEEE International Conference on (pp. 141-145). dx.doi.org/10.1109/icip.2016.7532335
Overview: The dataset contains 207 van Gogh and 124 non-van Gogh paintings, which were randomly split, forming a standard evaluation protocol. It also contains 2 paintings whose authorship are still under debate. To the best of our knowledge, we created the very first public dataset for painting identification with high quality images and density standardization. We gathered over 27,000 images from more than 200 categories in Wikimedia Commons. The code is also available on GitHub.
 UVAD Dataset
UVAD Dataset

Authors: Allan Pinto, William Robson Schwartz, Helio Pedrini and Anderson Rocha
Related publication: Pinto, A.; Schwartz, W.R.; Pedrini, H.; Rocha, A.d.R., Using Visual Rhythms for Detecting Video-Based Facial Spoof Attacks. Information Forensics and Security, IEEE Transactions on , vol.10, no.5, pp.1025,1038, May 2015. dx.doi.org/10.1109/TIFS.2015.2395139
Overview: In our work, we present a solution to video-based face spoofing to biometric systems. Such type of attack is characterized by presenting a video of a real user to the biometric system. Our approach takes advantage of noise signatures generated by the recaptured video to distinguish between fake and valid access. To capture the noise and obtain a compact representation, we use the Fourier spectrum followed by the computation of the visual rhythm and extraction of the gray-level co-occurrence matrices, used as feature descriptors. To evaluate the effectiveness of the proposed approach, we introduce the novel Unicamp Video-Attack Database (UVAD) which comprises 17, 076 videos composed of real access and spoofing attack videos. The code is also available on GitHub and the EULA agreement is available on FigShare.
 Diabetic Retinopathy Datasets
Diabetic Retinopathy Datasets

Authors: Ramon Pires, Herbert F. Jelinek, Jacques Wainer, Eduardo Valle and Anderson Rocha
Related publication: Pires, Ramon; F. Jelinek, Herbert; Wainer, Jacques; Valle, Eduardo; Rocha, Anderson (2014) Advancing Bag-of-Visual-Words Representations for Lesion Classification in Retinal Images. dx.doi.org/10.1371/journal.pone.0096814
Overview: Diabetic Retinopathy (DR) is a complication of diabetes that can lead to blindness if not readily discovered. The bag-of-visual-words (BoVW) algorithm employs a maximum-margin classifier in a flexible framework that is able to detect the most common DR-related lesions. In order to evaluate it, three large retinograph datasets (DR1, DR2 and Messidor) with different resolution and collected by different healthcare personnel, was adopted. The DR1 and DR2, provided by the Department of Ophthalmology, Federal University of São Paulo (Unifesp), each image was manually annotated. In DR1, the images were captured using a TRC-50X (Topcon Inc., Tokyo, Japan) mydriatic camera with maximum resolution of one megapixel (640×480 pixels) and a field of view (FOV) of 45°. In DR2, the dataset was captured using a TRC-NW8 retinograph with a Nikon D90 camera, creating 12.2 megapixel images, which were then reduced to 867×575 pixels for accelerating computation.
 Multimedia Phylogeny Datasets
Multimedia Phylogeny Datasets

Several datasets for Image/Text Phylogeny Trees and Forests Reconstruction. There are seven datasets for image phylogeny and two datasets for text phylogeny. The source code is also available here.
 Supermarket Produce Dataset
Supermarket Produce Dataset

Authors: Anderson Rocha, Daniel C. Hauagge, Jacques Wainer and Siome Goldenstein
Related publication: Rocha, A.; Hauagge, D. C.; Wainer, J.; Goldenstein, S.; Automatic fruit and vegetable classification from images. Computers and Electronics in Agriculture, Volume 70, Issue 1, January 2010, Pages 96-104. dx.doi.org/10.1016/j.compag.2009.09.002
Overview: The Supermarket Produce data set is the result of 5 months of on-site collecting in the local fruits and vegetables distribution center. The images were captured on a clear background at the resolution of 1024×768 pixels, using a Canon PowerShot P1 camera. For the experiments in this paper, they were downsampled to 640×480. The data set comprises 15 different categories: Plum (264), Agata Potato (201), Asterix Potato (182), Cashew (210), Onion (75), Orange (103), Taiti Lime (106), Kiwi (171), Fuji Apple (212), Granny-Smith Apple (155), Watermelon (192), Honeydew Melon (145), Nectarine (247), Williams Pear (159), and Diamond Peach (211); totalizing 2633 images.
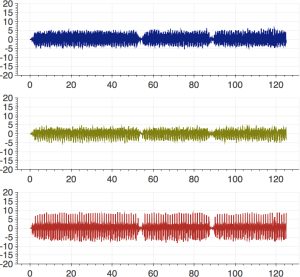 RECODGait Dataset
RECODGait Dataset
Authors: Geise Santos, Alexandre Ferreira and Anderson Rocha
Related publication: Santos, Geise. Técnicas para autenticação contínua em dispositivos móveis a partir do modo de caminhar, 2017. Master’s Thesis (in Portuguese)
Overview: The collected gait dataset comprises data from 50 volunteers of walking and non-walking activities collected with a LG Nexus 5 smartphone. For each volunteer, we collect their accelerometer data over two sessions of five minutes each under different acquisition conditions and in different days sampled in 40Hz. It contains raw data into three coordinate systems: device coordinates, world coordinates and user coordinates. More details are available in the readme.txt file.
Going Deeper into Copy-Move Forgery Detection
Authors: Ewerton Silva and Tiago Carvalho and Anselmo Ferreira and Anderson Rocha
Related publication: E. Silva, T. Carvalho A. Ferreira, and A. Rocha. Going deeper into copy-move forgery detection: exploring image telltales via multi-scale analysis and voting processes. Elsevier Journal of Visual Communication and Image Representation (JVCI). Volume 29. Pages 16-32. 2015. https://doi.org/10.1016/j.jvcir.2015.01.016
Overview: It presents a new approach toward copy-move forgery detection based on multi-scale analysis and voting processes of a digital image. Given a suspicious image, we extract interest points robust to scale and rotation finding possible correspondences among them. We cluster correspondent points into regions based on geometric constraints. Thereafter, we construct a multi-scale image representation and for each scale, we examine the generated groups using a descriptor strongly robust to rotation, scaling and partially robust to compression, which decreases the search space of duplicated regions and yields a detection map. The final decision is based on a voting process among all detection maps. The code is also available on GitHub.
Behavior Knowledge Space-Based Fusion for Copy-Move Forgery Detection
Authors: Anselmo Ferreira, Siovani C. Felipussi, Carlos Alfaro, Pablo Fonseca, John E. Vargas-Muñoz, Jefersson A. dos Santos, and Anderson Rocha
Related publication: A. Ferreira, S. Felipussi, C. Alfaro, P. Fonseca, J. E. Vargas-Munoz, J. A. dos Santos and A. Rocha. Behavior Knowledge Space-Based Fusion for Copy-Move Forgery Detection. IEEE Transactions on Image Processing (TIP). Volume 25, number 10. Pages 4729-4742. 2016. https://doi.org/10.1109/TIP.2016.2593583
Overview: We propose different techniques that exploit the multi-directionality of the data to generate the final outcome detection map in a machine learning decision-making fashion. Experimental results on complex data sets, comparing the proposed techniques with a gamut of copy–move detection approaches and other fusion methodologies in the literature, show the effectiveness of the proposed method and its suitability for real-world applications. The code is also available on GitHub.
Eyes on the Target: Super-Resolution and License-Plate Recognition in Low-Quality Surveillance Videos
Authors: Hilario Seibel Junior, Anderson Rocha, and Siome Goldenstein.
Related publication:
H. Seibel, S. Goldenstein, and A. Rocha, “Eyes on the Target: Super-Resolution and License-Plate Recognition in Low-Quality Surveillance Videos,” in IEEE Access, vol. 5, pp. 20020-20035, 2017. https://doi.org/10.1109/ACCESS.2017.2737418
H. Seibel, S. Goldenstein, and A. Rocha, “Fast and Effective Geometric K-Nearest Neighbors Multi-frame Super-Resolution,” 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, 2015, pp. 103-110. https://doi.org/10.1109/SIBGRAPI.2015.47
Overview: The dataset is a collection of 200 real-world traffic videos, in which the movement of the vehicles is away from the camera (one target license plate per video). All collected streams are 1080p HD videos @30 fps (video codec H.264, without additional compression) and contain only Brazilian license-plates. As we have a good resolution of the license plate in the beginning of each video, we manually identified the correct characters of its target license plate and created its ground-truth file. Unlike the beginning of the video, the license-plate alphanumerics in the last frames are harder to recognize. The videos were captured in different places, with different illumination conditions, different vehicle average speeds, non-stationary backgrounds, non-predictable routes, and containing trees and road signs that may cast different shadows over the license plates between consecutive frames. We also annotated information about the license-plate ROI to be recognized in those last frames: (1) The first frame in which the target license-plate have been considered for our algorithms; (2) The bounding box of the target license plate in such frame (four corners around the characters to be identified); (3) The orientation of the video (0 for landscape and 1 for portrait); (4) Color (0 if the color of the license-plate characters is lighter than the background, 1 otherwise); (5) The position of the separation between digits and letters inside the ROI (for Brazilian license-plates). Such information can also be recreated using the initialization step of our source-code. The dataset (including all videos, ground-truth files, license-plate annotations, and the OCR training files). The code is also available in this link.
